大语言模型的强化学习微调(RLHF/RLAIF)是当前 LLM 对齐(Alignment)的核心技术之一。从 InstructGPT 到 ChatGPT,再到 DeepSeek-R1,RL 在提升模型推理能力和人类偏好对齐方面发挥了关键作用。然而,不同 RL 算法的设计哲学和工程实现差异显著——PPO 需要四个模型协同训练,GRPO 去掉了 Critic 用组内相对奖励替代,而 DAPO 进一步针对训练后期的熵坍塌和信号稀疏问题进行了改进。
本文将结合字节跳动开源的 verl 框架,从数学原理到工程配置逐一剖析这三种算法,并分享在 GSM8K 数学推理任务上的实验对比结果。
实验记录:W&B Dashboard
背景:为什么需要强化学习?
预训练(Pretraining)赋予了模型广泛的语言知识,监督微调(SFT)让模型学会了遵循指令的格式。但仅靠这两个阶段,模型仍然会出现一些问题:生成看似合理但实际错误的内容(幻觉),产生有害或偏见性输出,以及在复杂推理任务上表现不稳定。
这些问题的根源在于,SFT 只是在模仿训练数据中的 token 分布,而没有一个显式的"好坏"信号来引导模型区分高质量和低质量的输出。强化学习通过引入奖励信号(Reward Signal),让模型在生成-评估-更新的循环中逐步优化策略,从而弥补了这一缺陷。
verl 框架简介
verl(Volcano Engine Reinforcement Learning for LLMs)是字节跳动开源的 LLM 强化学习训练框架。它的核心优势在于统一性——PPO、GRPO、DAPO 等算法共享同一套训练基础设施,切换算法只需修改少量配置参数。框架基于 Ray 实现分布式调度,集成 vLLM 加速 rollout 推理,并支持 Rule-based Reward 和 Reward Model 两种奖励方式。
在我们的实验中,三种算法的训练脚本共享同一组基础参数(模型路径、学习率、batch size 等),仅在算法特有的配置上有所差异。这使得实验对比更加公平和可控。
PPO:Proximal Policy Optimization
算法原理
PPO 由 Schulman et al. (2017) 提出,是强化学习中最经典的策略梯度算法之一。它也是 RLHF 中最早被大规模使用的方法——InstructGPT (Ouyang et al., 2022) 和 ChatGPT 背后都采用了 PPO。
策略梯度方法的核心思路是:沿着能让 Advantage 为正的动作的概率增大的方向更新参数。但朴素的策略梯度(如 REINFORCE)在更新步长上缺乏约束,容易出现策略崩溃。PPO 的核心创新是引入了 Clipped Surrogate Objective,通过裁剪概率比来限制每次更新的幅度:
$$ \mathcal{L}^{\text{PPO}}(\theta) = \mathbb{E}_t \left[ \min \left( r_t(\theta) \hat{A}_t, \; \text{clip}\big(r_t(\theta),\; 1-\epsilon,\; 1+\epsilon\big) \hat{A}_t \right) \right] $$其中 $r_t(\theta) = \pi_\theta(a_t|s_t) / \pi_{\theta_{\text{old}}}(a_t|s_t)$ 是新旧策略的概率比,$\hat{A}_t$ 是通过 GAE(Generalized Advantage Estimation)计算的优势函数,$\epsilon$ 是裁剪系数(通常取 0.2)。
直觉上,当 $r_t(\theta)$ 偏离 1 太远时(即新策略和旧策略差异过大),裁剪机制会阻止目标函数继续增长,从而让优化器不再有动力朝那个方向更新。
KL 散度惩罚
在 RLHF 场景中,PPO 还会加入一个 KL 散度惩罚项,防止训练后的策略偏离参考模型(通常是 SFT checkpoint)太远。完整的优化目标为:
$$ \mathcal{L}^{\text{PPO-RLHF}}(\theta) = \mathcal{L}^{\text{PPO}}(\theta) - \beta \cdot D_{\text{KL}}\left(\pi_\theta \;\|\; \pi_{\text{ref}}\right) $$参数 $\beta$ 控制 KL 惩罚的强度。设置过大会限制模型学习新行为,过小则可能导致 reward hacking。
四个模型的计算开销
PPO 在 RLHF 中需要同时维护四个模型,这是它最大的工程挑战:
| 模型 | 作用 | 是否更新 |
|---|---|---|
| Actor(Policy Model) | 生成回复,是被优化的目标 | ✅ 训练更新 |
| Critic(Value Model) | 估计状态价值 $V(s)$,用于计算 GAE Advantage | ✅ 训练更新 |
| Reward Model | 对生成的回复进行打分 | ❌ 冻结 |
| Reference Model | 提供 KL 惩罚的参考分布 | ❌ 冻结 |
四个模型意味着显存占用是 SFT 的数倍。一个常见的工程技巧是:Critic 不必和 Actor 使用同规模的模型。在我们的实验中,Actor 使用 Qwen2.5-7B,而 Critic 使用 Qwen2.5-0.5B-Instruct,显著降低了显存需求。
verl 中的 PPO 配置
以下是我们实验中 PPO 的核心配置(完整脚本见附录):
data:
train_batch_size: 256
max_prompt_length: 512
max_response_length: 512
actor_rollout_ref:
model:
path: Qwen2.5-7B
actor:
optim.lr: 1e-6
ppo_mini_batch_size: 64
ppo_micro_batch_size_per_gpu: 16
rollout:
name: vllm
tensor_model_parallel_size: 1
gpu_memory_utilization: 0.4
ref:
log_prob_micro_batch_size_per_gpu: 4
critic:
model:
path: Qwen2.5-0.5B-Instruct # Critic 使用 0.5B 小模型
optim.lr: 1e-5
ppo_micro_batch_size_per_gpu: 4
algorithm:
kl_ctrl.kl_coef: 0.001
trainer:
n_gpus_per_node: 4
total_epochs: 15
test_freq: 10
值得注意的是,Critic 的学习率(1e-5)比 Actor(1e-6)高一个量级——Value Function 需要更快地适应策略变化,否则 Advantage 估计会严重滞后。
GRPO:Group Relative Policy Optimization
算法原理
GRPO 由 DeepSeek 在 DeepSeekMath 中提出 (Shao et al., 2024),核心动机非常直接:能否去掉 Critic 模型,用更简单的方式估计 Advantage?
答案是肯定的。GRPO 的做法是:对于每个 prompt $q$,采样一组(Group)回复 $\\{o_1, o_2, \dots, o_G\\}$,用 Reward Model 或规则对每个回复打分得到 $\\{r_1, r_2, \dots, r_G\\}$,然后通过组内标准化来估计 Advantage:
$$ \hat{A}_i = \frac{r_i - \text{mean}(r_1, \dots, r_G)}{\text{std}(r_1, \dots, r_G)} $$这个设计的直觉是:我们不需要知道一个回复的绝对好坏,只需要知道它在同一 prompt 的一组回复中相对排名如何。如果某个回复的奖励高于组内平均,它的 Advantage 就为正,策略会被鼓励生成类似的回复;反之则被抑制。
GRPO 的优化目标
完整的 GRPO 目标函数为:
$$ \mathcal{L}^{\text{GRPO}}(\theta) = \mathbb{E}_{q,\, \lbrace o_i \rbrace} \left[ \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|o_i|}\sum_{t=1}^{|o_i|} \min \left( r_{i,t}(\theta) \hat{A}_i, \; \text{clip}\big(r_{i,t}(\theta),\; 1-\epsilon,\; 1+\epsilon\big) \hat{A}_i \right) \right] - \beta \cdot D_{\text{KL}} $$其中概率比 $r_{i,t}(\theta) = \pi_\theta(o_{i,t} \mid q, o_{i,\lt t}) / \pi_{\theta_{\text{old}}}(o_{i,t} \mid q, o_{i,\lt t})$。KL 散度采用逐 token 计算的形式:
$$ D_{\text{KL}}(\pi_\theta \;\|\; \pi_{\text{ref}}) = \sum_t \left[ \frac{\pi_{\text{ref}}(o_{i,t} \mid q, o_{i,\lt t})}{\pi_\theta(o_{i,t} \mid q, o_{i,\lt t})} - \log \frac{\pi_{\text{ref}}(o_{i,t} \mid q, o_{i,\lt t})}{\pi_\theta(o_{i,t} \mid q, o_{i,\lt t})} - 1 \right] $$这是 KL 散度的一种无偏估计,具有数值稳定性好、计算简单的优点。
GRPO vs PPO:关键差异
| 维度 | PPO | GRPO |
|---|---|---|
| Critic 模型 | 需要,用于 GAE 估计 | 不需要 |
| 活跃模型数 | 4 | 3 |
| Advantage 估计 | GAE(基于 Value Function) | 组内相对奖励标准化 |
| 每个 prompt 采样数 | 1(通常) | 多个(如 8、16、64) |
| 显存占用 | 高 | 较低 |
| 对 Reward 的要求 | 通用 | 需要有区分度的 reward |
去掉 Critic 带来的好处不仅是省显存。Critic 的训练本身就是一个难题——如果 Value Function 估计不准,GAE 计算出的 Advantage 也会有偏,进而影响策略更新质量。GRPO 用统计量(组内均值和标准差)替代了学习得到的 Value Function,在 reward 信号足够清晰的场景(如数学题的对错判断)下是一个优雅的简化。
verl 中的 GRPO 配置
从 PPO 切换到 GRPO 只需要修改很少的配置:
algorithm:
adv_estimator: grpo # 切换 Advantage 估计方式
actor_rollout_ref:
rollout:
n: 8 # 每个 prompt 采样 8 个回复
gpu_memory_utilization: 0.5 # 多采样需要更多推理显存
其余配置(模型路径、学习率、batch size 等)与 PPO 完全相同。注意 gpu_memory_utilization 从 0.4 提升到了 0.5,因为每个 prompt 需要生成 8 个回复,vLLM 的 KV cache 占用相应增大。同时,GRPO 不需要 Critic 配置段,省掉了一个模型的显存和计算。
DAPO:Decoupled Clip and Dynamic Sampling Policy Optimization
算法原理
DAPO 由 ByteDance Seed 团队提出 (Yu et al., 2025),全称是 Decoupled Clip and Dynamic sAmpling Policy Optimization。它在 GRPO 的基础上,针对大规模 RL 训练中暴露出的两个核心问题进行了改进:
- 熵坍塌(Entropy Collapse):训练后期策略的输出多样性急剧下降,模型反复生成相似的回复,探索能力丧失。
- 训练信号稀疏:当某个 prompt 的所有采样全部答对或全部答错时,组内标准化后的 Advantage 为零(标准差为零或全部相同),这个 prompt 对梯度没有贡献。
DAPO 的四项关键技术
1. Clip-Higher(非对称裁剪)
标准 PPO/GRPO 使用对称裁剪区间 $[1-\epsilon, 1+\epsilon]$。DAPO 将上下界解耦,采用非对称裁剪:
$$ \mathcal{L}^{\text{clip}}(\theta) = \min \left( r_t(\theta) \hat{A}_t, \; \text{clip}\big(r_t(\theta),\; 1-\epsilon_{\text{low}},\; 1+\epsilon_{\text{high}}\big) \hat{A}_t \right) $$其中 $\epsilon_{\text{high}} > \epsilon_{\text{low}}$(例如 $\epsilon_{\text{low}}=0.2,\; \epsilon_{\text{high}}=0.28$)。
这样做的效果是:对于 Advantage 为正的动作(好的回复),允许策略做更大幅度的更新;对于 Advantage 为负的动作(差的回复),保持较保守的更新。这有效缓解了熵坍塌问题——策略不会被过度约束在当前的输出分布附近。同时,DAPO 去除了熵正则化项(entropy bonus),完全依赖 Clip-Higher 机制来维持探索。
2. Dynamic Sampling(动态采样过滤)
对于每个训练 batch 中的 prompt,DAPO 会计算其采样组的准确率 $\text{acc}(q)$,然后过滤掉全对或全错的组:
$$ \text{filtered prompts} = \lbrace q : 0 \lt \text{acc}(q) \lt 1 \rbrace $$直觉很清楚:如果所有采样都答对了,这个 prompt 已经"学会了",无法提供有效的对比信号;如果全部答错,模型暂时还无法解决这个问题,强行用零信号更新反而可能引入噪声。只保留有区分度的 prompt 组,确保每个梯度更新都包含有意义的信息。
为了维持有效的 batch size,DAPO 会动态调整采样数量,确保过滤后仍有足够的训练样本。
3. Token-level Loss(消除长度偏置)
标准实现中,loss 是在 sequence 级别取平均的,即先对每个回复内的 token loss 求平均,再对组内所有回复求平均。这会引入长度偏置——短回复的每个 token 获得的梯度更大,模型可能会倾向于生成更短的回复。
DAPO 改为在所有 token 上直接取平均:
$$ \mathcal{L}^{\text{DAPO}} = \frac{1}{\sum_{i=1}^{G} |o_i|} \sum_{i=1}^{G} \sum_{t=1}^{|o_i|} \mathcal{L}^{\text{clip}}_{i,t} $$这样,每个 token 的贡献是均等的,不会因为回复长度不同而产生偏差。
4. Overlong Reward Shaping(超长惩罚)
对于超过最大长度限制而被截断的回复,直接标记为"错误"会引入噪声(因为截断的回复不一定推理方向是错的,只是没写完)。DAPO 采用软惩罚策略:
$$ r_i = \begin{cases} r_i^{\text{original}} & \text{if } |o_i| < L_{\text{max}} \\ r_{\text{penalty}} & \text{if } |o_i| \geq L_{\text{max}} \end{cases} $$这既惩罚了冗长输出,又不会完全抹杀长回复中可能存在的有效推理信号。
verl 中的 DAPO 配置
在 verl 中启用 DAPO,需要在 GRPO 基础上修改 reward 管理和采样配置:
algorithm:
adv_estimator: grpo # 复用 GRPO 的 Advantage 框架
actor_rollout_ref:
rollout:
n: 16 # 更多采样以支持动态过滤
gpu_memory_utilization: 0.6
reward_model:
reward_manager: dapo # 启用 DAPO 的 Reward Manager
reward_kwargs:
max_resp_len: 1024 # 允许更长的回复(基础配置为 512)
overlong_buffer_cfg:
enable: True
len: 512 # 超长缓冲区长度
penalty_factor: 1.0
log: True
关键点在于 reward_manager: dapo——DAPO 的 Dynamic Sampling、Token-level Loss 等逻辑封装在专用的 Reward Manager 内部实现,而非通过额外的配置参数暴露。max_resp_len 被设为 1024(比基础的 max_response_length=512 更长),配合 overlong_buffer_cfg 实现截断回复的软惩罚。采样数从 GRPO 的 8 提升到 16,是因为 Dynamic Sampling 会过滤掉一部分 prompt 组,需要更多初始样本来保持有效 batch size。
三种算法对比总结
| 维度 | PPO | GRPO | DAPO |
|---|---|---|---|
| 提出 | Schulman et al., 2017 | Shao et al., 2024 | Yu et al., 2025 |
| Critic 模型 | 需要 | 不需要 | 不需要 |
| 活跃模型数 | 4 | 3 | 3 |
| Advantage 估计 | GAE(Value Function) | 组内相对标准化 | 组内相对标准化 |
| 裁剪方式 | 对称 $[1-\epsilon, 1+\epsilon]$ | 对称 | 非对称 Clip-Higher |
| 采样策略 | 每 prompt 1 个回复 | 每 prompt 多个,全部使用 | 每 prompt 多个,动态过滤 |
| Loss 粒度 | Sequence-level | Sequence-level | Token-level |
| 超长处理 | 截断即错 | 截断即错 | 软惩罚 |
| 显存占用 | 最高 | 中等 | 中等 |
三种算法之间存在清晰的演化关系:
PPO
经典策略梯度算法
需要 Critic(4 模型)
GAE 估计 Advantage
组内相对奖励
GRPO
无 Critic(3 模型)
组内标准化 Advantage
每 prompt 多次采样
动态采样
Token-level Loss
DAPO
Clip-Higher 抗熵坍塌
Dynamic Sampling
Overlong Shaping
GSM8K 实验
我们使用 verl 框架在 GSM8K 小学数学推理数据集上对三种算法进行了对比。GSM8K 的 Reward 是 Rule-based 的:将模型输出的最终数值答案与标准答案精确匹配,正确得分 1,错误得分 0。这种二值 reward 使得组内相对奖励的信号非常清晰,有利于 GRPO 和 DAPO。
实验设置
| 配置 | 值 |
|---|---|
| Actor 模型 | Qwen2.5-7B |
| Critic 模型(仅 PPO) | Qwen2.5-0.5B-Instruct |
| 数据集 | GSM8K(训练集 7.4K,测试集 1.3K) |
| Reward | Rule-based 答案精确匹配 |
| Rollout 引擎 | vLLM |
| GPU | 4 卡 |
| 训练轮数 | 15 epochs(共 435 steps) |
| 验证频率 | 每 10 步 |
| Actor 学习率 | 1e-6 |
| Critic 学习率(仅 PPO) | 1e-5 |
| KL 系数 | 0.001 |
| 采样数 | PPO: 1 / GRPO: 8 / DAPO: 16 |
详细训练曲线请查看 W&B Dashboard。
实验结果
三个 run 均成功完成 15 个 epoch(435 steps)的训练。
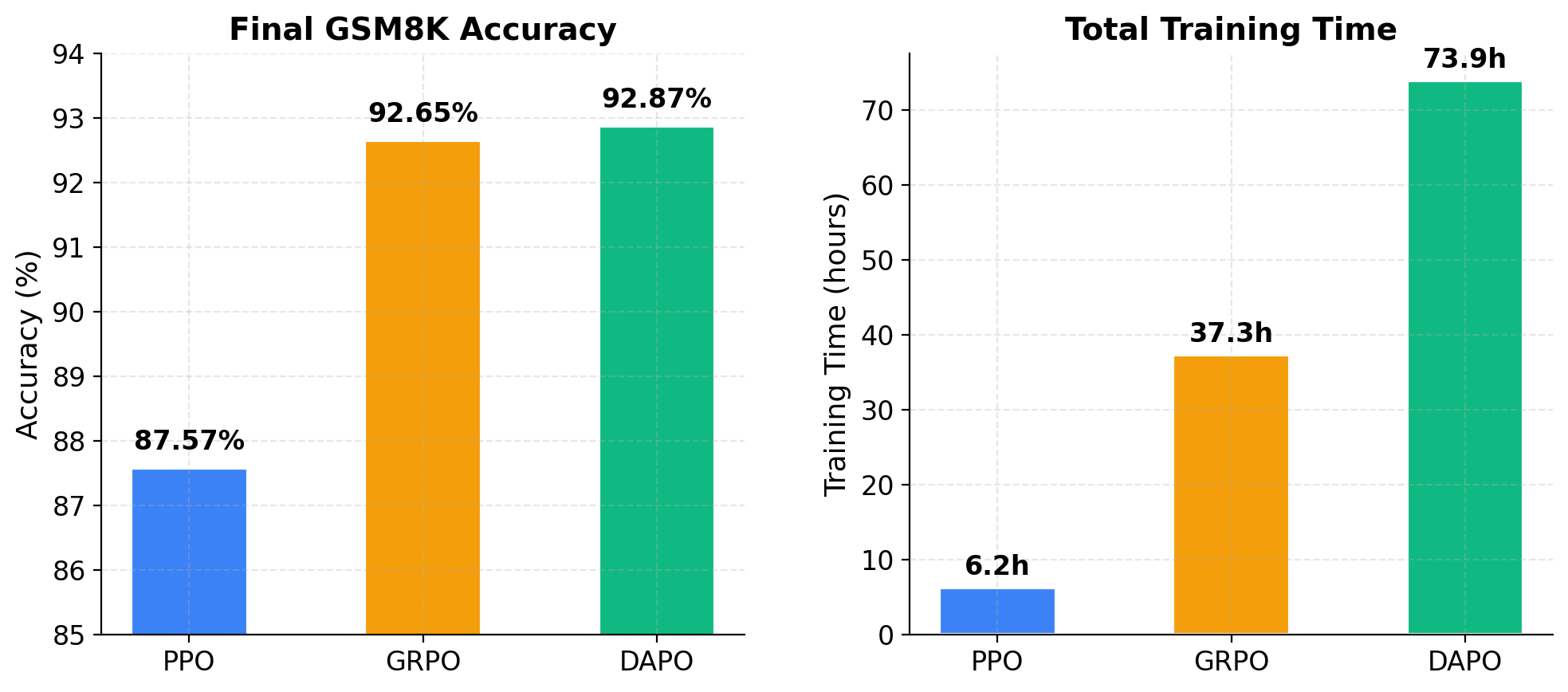
Fig. 1 — 最终 GSM8K Accuracy(左)与总训练时间(右)对比。DAPO 达到最高精度 92.87%,PPO 训练最快仅 6.2h。
完整指标表格(点击展开)
| 指标 | PPO | GRPO | DAPO |
|---|---|---|---|
| 最终 GSM8K Accuracy | 87.57% | 92.65% | 92.87% |
| 最高 Accuracy(训练过程中) | 90.98% (step 240) | 92.65% (step 435) | 92.87% (step 435) |
| 总训练时间 | 6.2 h | 37.3 h | 73.9 h |
| 最终 Policy Entropy | 0.0284 | 0.0266 | 0.0233 |
| 最终 KL Divergence | 3.29e-4 | 1.94e-4 | 3.91e-4 |
| 最终 Policy Clip Fraction | 2.87e-3 | 1.96e-4 | 2.39e-4 |
训练过程分析
下面是三种算法在验证集上的 Accuracy 变化趋势:
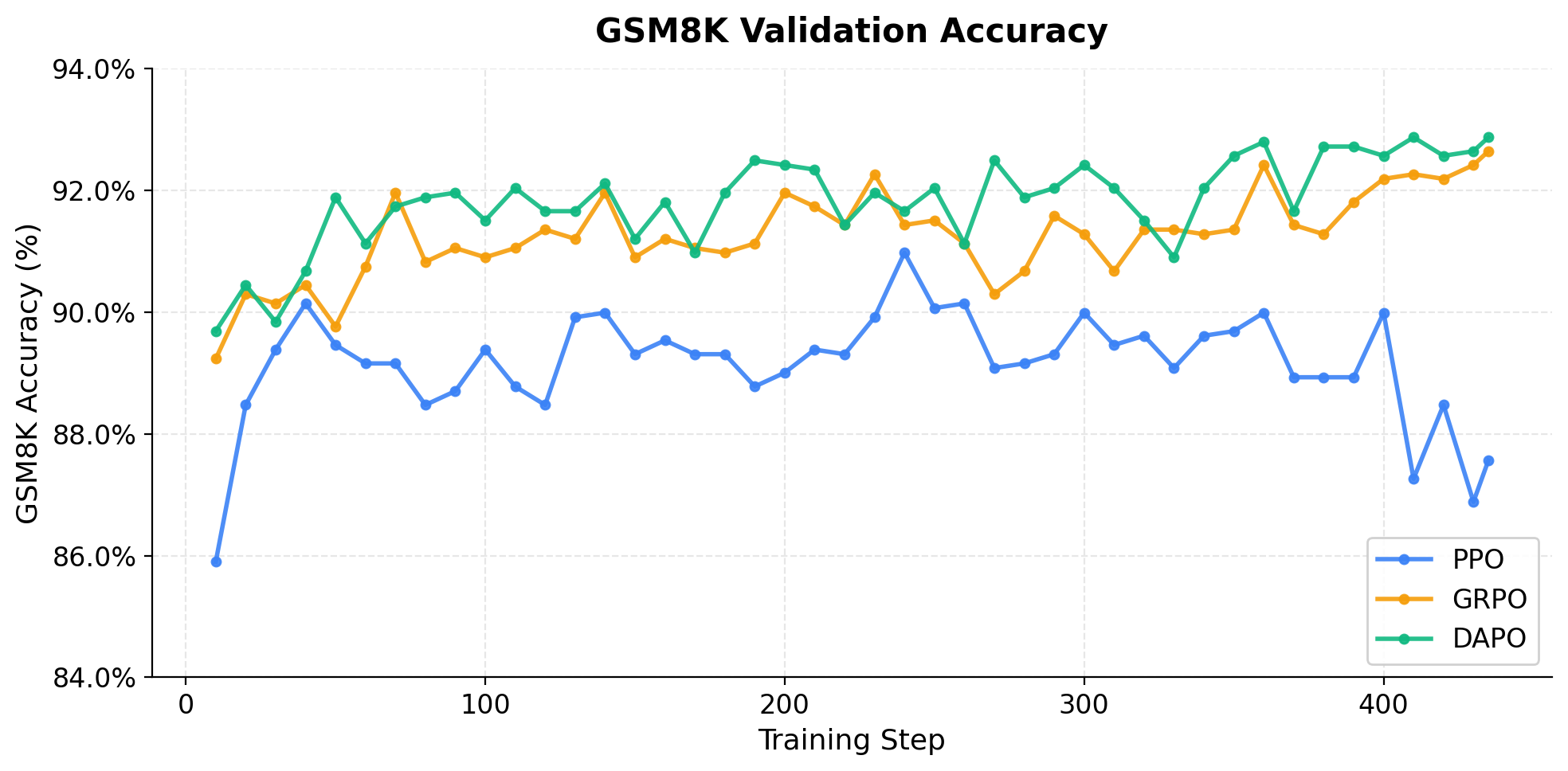
Fig. 2 — GSM8K Validation Accuracy 训练曲线。PPO(蓝色)在 step 240 达到峰值后持续下降;GRPO(黄色)呈平稳上升趋势;DAPO(绿色)早期学习最快,在 step 50 就达到 91.89%。
完整训练数据表格(点击展开)
PPO Validation Reward:
| Step | Reward | Step | Reward | Step | Reward |
|---|---|---|---|---|---|
| 10 | 85.90% | 150 | 89.31% | 300 | 89.99% |
| 30 | 89.39% | 200 | 89.01% | 350 | 89.69% |
| 50 | 89.46% | 240 | 90.98% | 400 | 89.99% |
| 100 | 89.39% | 250 | 90.07% | 435 | 87.57% |
GRPO Validation Reward:
| Step | Reward | Step | Reward | Step | Reward |
|---|---|---|---|---|---|
| 10 | 89.23% | 150 | 90.90% | 300 | 91.28% |
| 30 | 90.14% | 200 | 91.96% | 360 | 92.42% |
| 50 | 89.76% | 230 | 92.27% | 400 | 92.19% |
| 100 | 90.90% | 250 | 91.51% | 435 | 92.65% |
DAPO Validation Accuracy:
| Step | Acc | Step | Acc | Step | Acc |
|---|---|---|---|---|---|
| 10 | 89.69% | 150 | 91.21% | 300 | 92.42% |
| 30 | 89.84% | 200 | 92.42% | 360 | 92.80% |
| 50 | 91.89% | 250 | 92.04% | 410 | 92.87% |
| 100 | 91.51% | 270 | 92.49% | 435 | 92.87% |
DAPO 的 overlong 比例在整个训练过程中始终为 0.0%,说明 GSM8K 的回复长度在控制范围内。
训练指标快照
下面对比 step 100(训练初期)和 step 400(训练后期)时三种算法的关键训练指标:
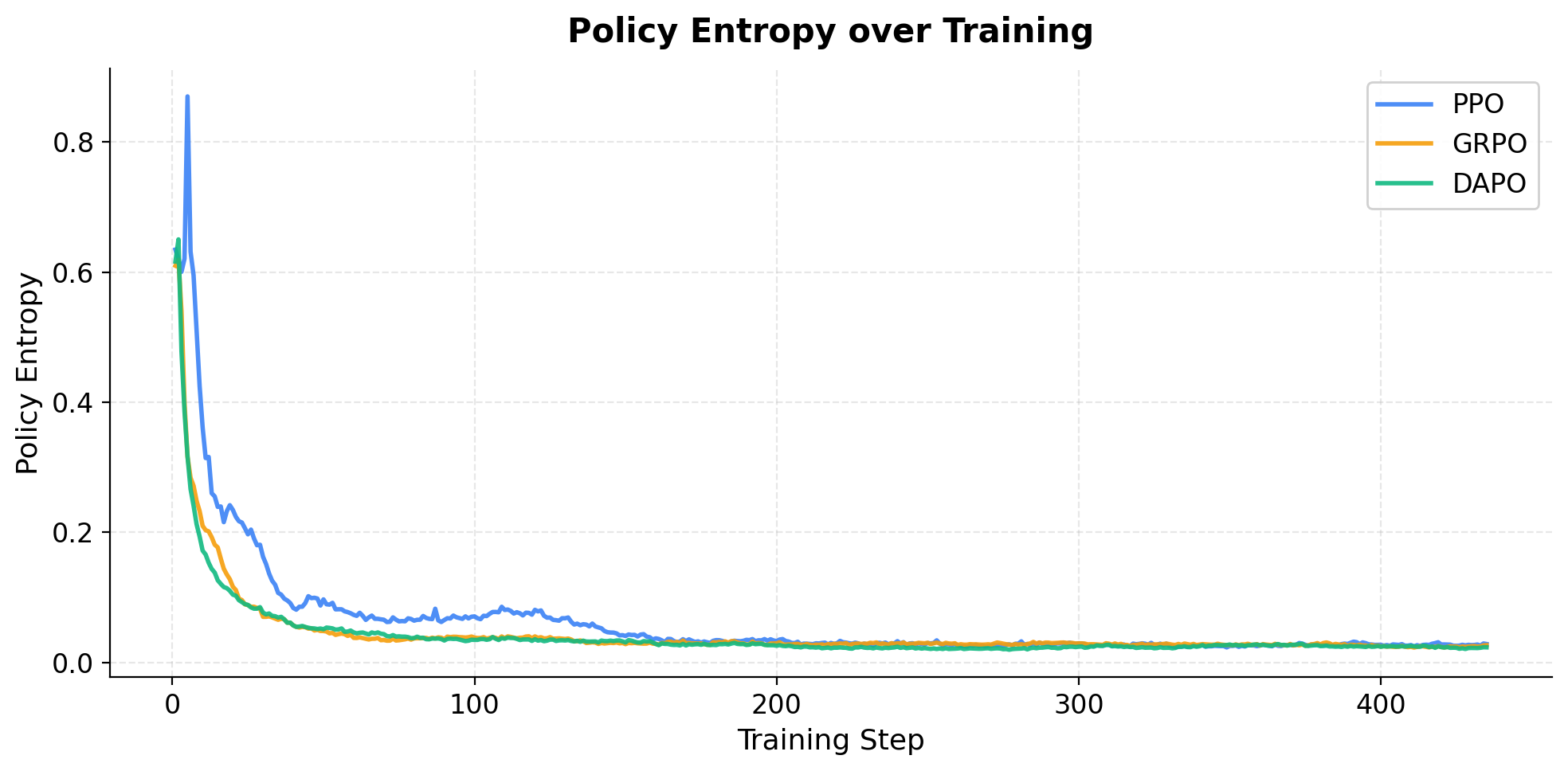
Fig. 3 — Policy Entropy 变化曲线。PPO 初期 entropy 约为 GRPO/DAPO 的 2 倍,但最终三者趋于一致。
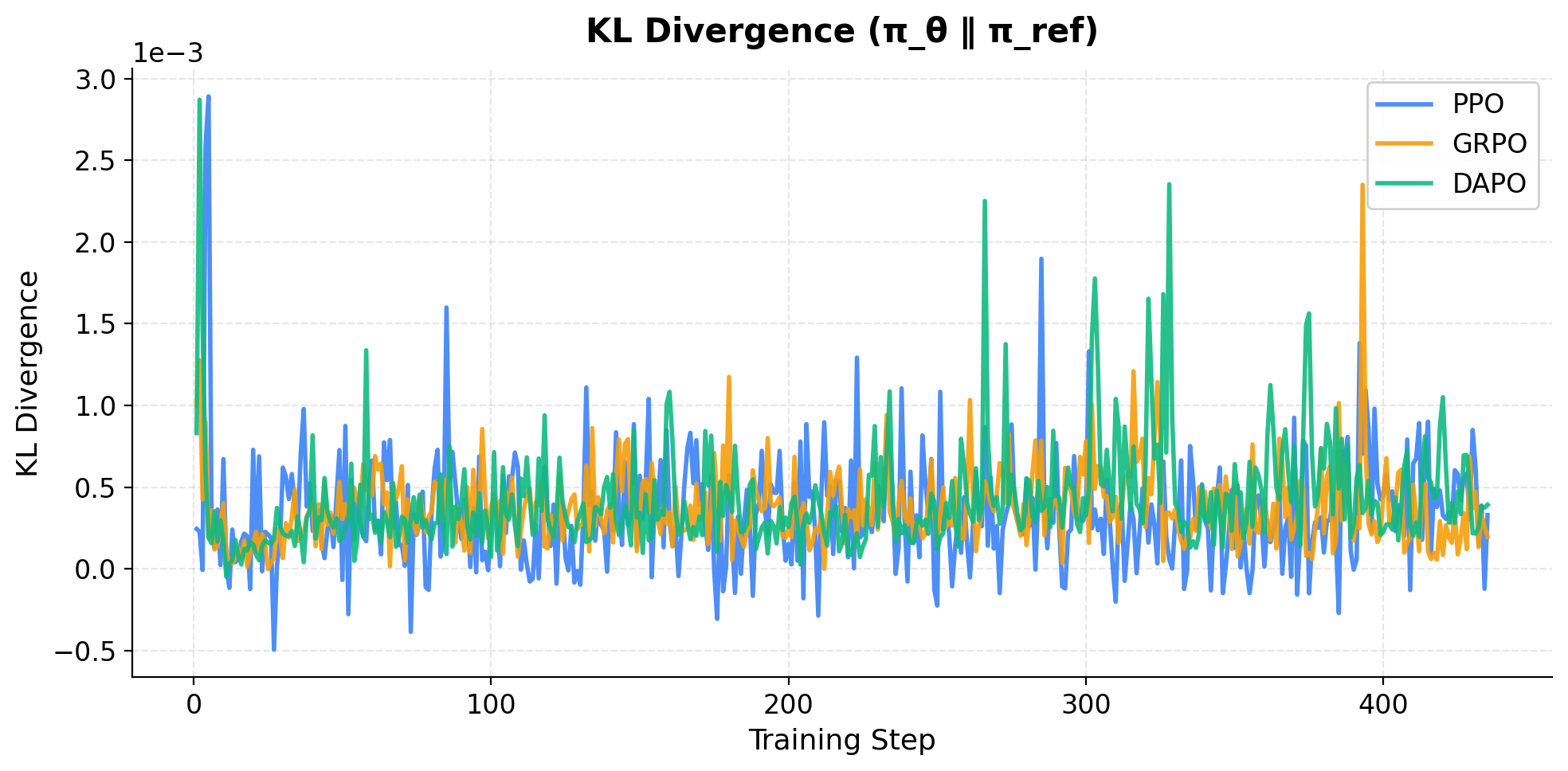
Fig. 4 — KL Divergence(π_θ ∥ π_ref)曲线。DAPO 在训练过程中始终维持最低的 KL 散度。
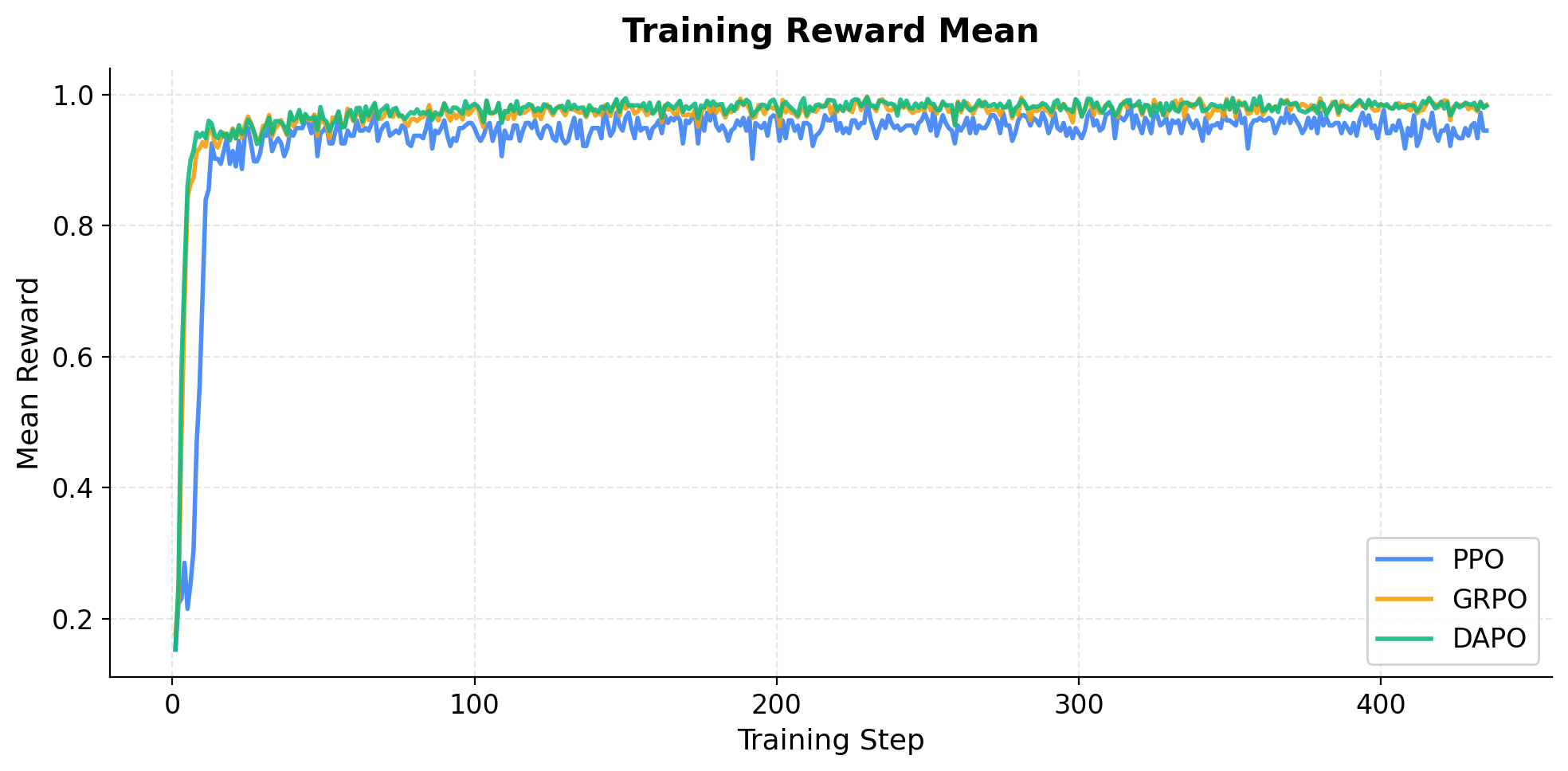
Fig. 5 — Training Reward Mean 曲线。GRPO 和 DAPO 的 reward 迅速攀升至 0.98 以上,PPO 则稳定在 0.95 左右。
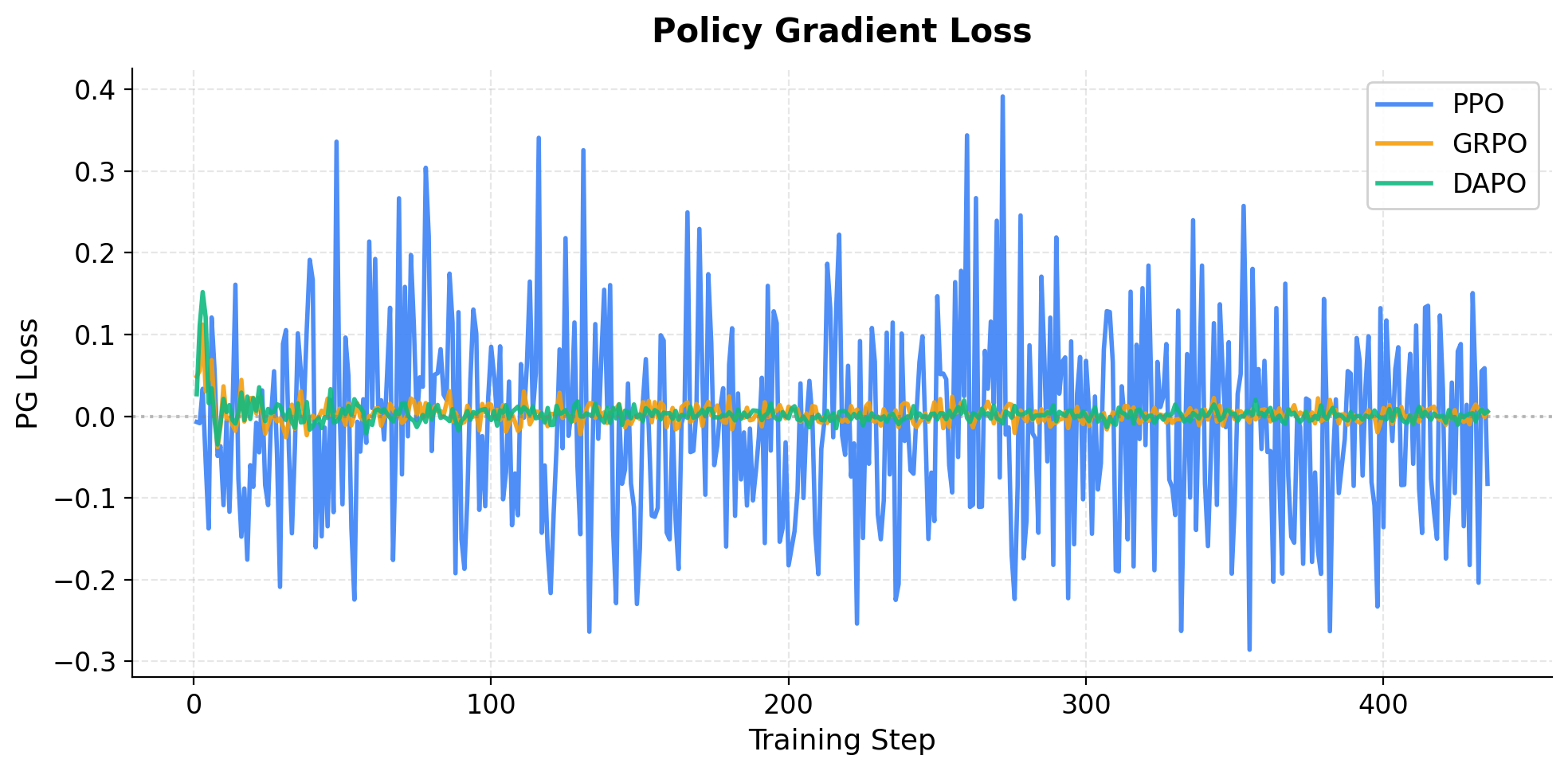
Fig. 6 — Policy Gradient Loss 曲线。PPO 的 pg_loss 波动最大,后期转为负值;GRPO/DAPO 保持在零附近,更新更稳定。
完整训练指标表格(点击展开)
| 指标 (step 100) | PPO | GRPO | DAPO |
|---|---|---|---|
| actor/entropy | 0.0709 | 0.0383 | 0.0347 |
| actor/pg_loss | 0.0849 | 0.0140 | -0.0046 |
| actor/ppo_kl | 3.10e-4 | 3.76e-4 | 7.2e-5 |
| critic/rewards/mean | 0.9492 | 0.9819 | 0.9863 |
| 指标 (step 400) | PPO | GRPO | DAPO |
|---|---|---|---|
| actor/entropy | 0.0272 | 0.0246 | 0.0242 |
| actor/pg_loss | -0.1359 | 0.0099 | -0.0023 |
| actor/ppo_kl | 4.48e-4 | 4.65e-4 | 2.25e-4 |
| critic/rewards/mean | 0.9570 | 0.9858 | 0.9854 |
关键观察
PPO 表现出了最快的挂钟时间(wall-clock time),仅 6.2 小时即完成全部 15 个 epoch。这是因为每个 prompt 只采样 1 个回复,rollout 阶段的开销远小于 GRPO 和 DAPO。然而,PPO 的最终准确率(87.57%)是三者中最低的,并且训练后期出现了明显的性能回落——从 step 240 的峰值 90.98% 下降到最终的 87.57%,降幅超过 3 个百分点。这可能与 Critic 的 Value Function 估计偏差在训练后期放大有关——我们使用的 Critic 模型(0.5B)远小于 Actor(7B),其表示能力可能不足以准确追踪后期越来越精细的策略变化。PPO 的 policy clip fraction(2.87e-3)是三者中最高的,约为 GRPO 的 15 倍,说明策略更新幅度偏大、稳定性欠佳。
GRPO 达到了 92.65% 的最终准确率,相比 PPO 提升了约 5 个百分点。训练曲线呈现出平稳上升的趋势——从 step 10 的 89.23% 一路攀升到最终的 92.65%,几乎没有明显回落。训练耗时 37.3 小时,约为 PPO 的 6 倍,主要开销来自每个 prompt 采样 8 个回复的 rollout 阶段。从训练指标来看,GRPO 的 policy clip fraction 极低(1.96e-4),pg_loss 始终维持在小正值(0.014→0.010),反映出策略更新非常平滑。训练过程中的 reward mean 从 0.93 迅速提升到 0.98 以上,表明模型很快学会了 GSM8K 的解题模式。
DAPO 取得了最高的 92.87% 准确率,略优于 GRPO。几个值得关注的现象:(1) DAPO 在训练早期(step 50)就达到了 91.89%,比同期的 PPO(89.46%)和 GRPO(89.76%)都要高,说明更多采样(n=16)带来的信号质量提升在初期尤为明显;(2) DAPO 的 KL 散度在 step 100 时仅为 7.2e-5,远低于 PPO(3.10e-4)和 GRPO(3.76e-4),说明 DAPO 在更新策略的同时能更好地控制对参考模型的偏离;(3) overlong 比例始终为 0.0%,说明 GSM8K 的回复长度天然较短,overlong reward shaping 机制虽然激活了但没有实际触发;(4) DAPO 的 entropy(0.0233)是三者中最低的,但并未出现性能退化,说明 Clip-Higher 机制在低 entropy 状态下仍维持了策略的有效性。训练时间(73.9 小时)是三者中最长的,约为 GRPO 的 2 倍、PPO 的 12 倍。
综合来看,在 GSM8K 这个 reward 信号清晰的数学推理任务上,DAPO ≈ GRPO » PPO,而 PPO 胜在训练速度最快。选择哪种算法取决于对精度和训练成本的权衡。
总结与实践建议
从 PPO 到 GRPO 再到 DAPO,我们可以看到 LLM 强化学习算法的一条清晰演化路径:在保持训练稳定性的前提下,尽可能减少计算开销、提高梯度信号质量。
几点实践建议:
- 任务有可验证的 reward(如数学答案、代码测试用例):优先尝试 DAPO > GRPO > PPO。GRPO/DAPO 的组内相对奖励在这类任务上信号清晰,不需要额外训练 Critic。
- 任务只有 Reward Model(如对话偏好评分):PPO 仍然是可靠的选择。Reward Model 的打分是连续值,组内标准化的效果可能不如 GAE 稳定。
- 显存受限:GRPO 是最佳选择。它去掉了 Critic,显存占用最低。DAPO 虽然也不需要 Critic,但更多的采样数会增加 vLLM 的推理显存。
- verl 框架的优势:算法切换只需修改
adv_estimator和少量参数,共享同一套分布式基础设施,非常适合算法对比研究。
参考文献
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347.
- Ouyang, L., Wu, J., Jiang, X., et al. (2022). Training language models to follow instructions with human feedback. NeurIPS 2022.
- Shao, Z., Wang, P., Zhu, Q., et al. (2024). DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300.
- Yu, Q., Zhang, Z., Zhu, R., et al. (2025). DAPO: An Open-Source LLM Reinforcement Learning System. arXiv:2503.14476.
- verl: Volcano Engine Reinforcement Learning for LLMs. GitHub Repository.